
ASCII vs Unicode
What is the main difference between ASCII and Unicode? The answer to this question is quite basic, but still not many software developers are aware of it and make mistakes while coding.
The following sections will talk in detail about Unicode vs ASCII differences that will help programmers deal with text easily.
What is ASCII?
Any electronic communication device reads data as electric pulses, as on and off. This on and off is represented in digital terms as 1 and 0 respectively.
A representation of data in terms of 1’s and 0’s is called binary representation. Anything you type on a computer is stored in the form of these two numbers only.
In early years of computing the only language known to computer programmers was English (since computers and everything related to it was invented in USA). Hence, for computer encoders a total of 127-128 characters were more than enough to represent everything that was there on the keyboard.
Computer encoders developed ASCII – American Standard Code for Information Exchange, an encoding standard. This standard was used to encode a certain number of characters, 127 to be exact.
These 127 characters included:
A-Z, a-z, 0-9, punctuation marks, new line characters and so on.

Later on an extended form of ASCII was developed that supported 256 characters and not just 128 characters. This extended ASCII was not a standard version and had many localized versions like ISO Latin 1 for some European languages, ISO-8859-2 for Eastern European languages.
ASCII was developed to support just one language – English. Different versions of Extended ASCII supported languages that had their origins in Latin.
Check Out: Difference Between ITX and ATX: ITX vs ATX Motherboards
What is Unicode?
With the internationalization of the computing world and development of the World Wide Web, computers no longer remained the domain of English speaking countries. Hence, a need was felt for an encoding standard that would encompass the character set of the various languages spoken throughout.
A non-profit organization, the Unicode consortium was formed that developed a universal encoding standard. This standard was called Unicode.
In Unicode encoding standard, there is a number for every character. The latest version of Unicode has 137, 929 characters. It includes languages like Armenian, Greek, and Arabic and so on.

Go to the Unicode site to get the latest code charts. They are available online and organized script wise. A character index is also available for quick reference.
As you can see, Unicode shows in a tabular form the numbers given to different characters. But, it does not tell a computer how to store it. It will depend upon the programmer which encoding scheme he wants to use.
The encoding schemes available under Unicode are:
UTF-8 – Uses 8 bits or 1 byte to store a character’s representation, for example, A will be stored as 01000001.
UTF-16 – Uses 16 bits or 2 bytes to store a character’s representation, for example, A will be stored as 00000000 01000001.
UTF-32 – Uses 32 bits or 4 bytes to store a character’s representation, for example, A will be stored as 00000000 00000000 00000000 01000001.
As you can see UTF-32 requires the maximum space. Hence, depending upon the script and programming needs, a programmer can choose to write his code using a particular UTF scheme.
Unicode is not encoding like ASCII. It is just a set of code charts.
Difference Between ASCII and Unicode
Here is a comparative ASCII vs Unicode table for easy reference:
| Point of Difference | ASCII | Unicode |
| Full form | American Standard Code for Information Exchange | Universal Character Set |
| Definition | Encoding standard for characters to be used in computers and other electronic media | A database of the numbers assigned to different characters |
| Characters supported | 128 | Can support up to 1,114,112 characters |
| Number of bytes used | 1 byte or 8 bits | 1,2 or 4 bytes – it will depend upon the encoding standard used |
| Subset or superset | ASCII is a subset of Unicode | Unicode is a superset and has UTF-8 for ASCII compatibility |
| Memory usage | Requires less memory | Requires more memory |
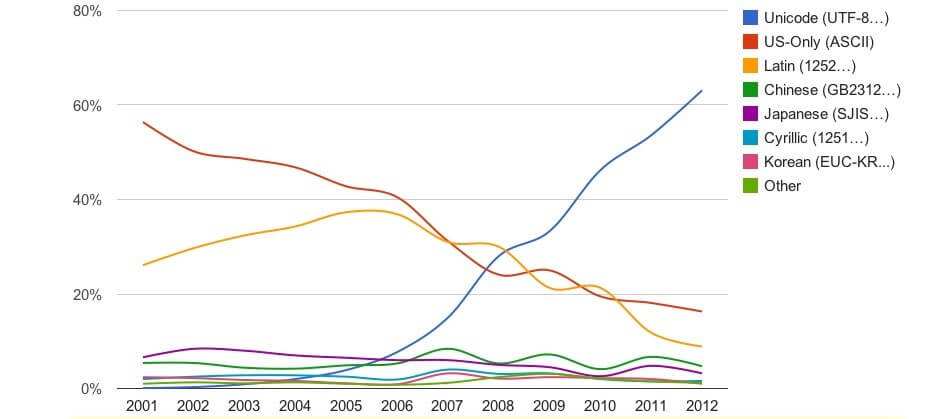
Today, most of the websites are using UTF-8 as their encoding standard.
Read: What is the Difference Between Frequency and Bandwidth?
Wrapping it up: ASCII vs Unicode Difference
Hopefully, the above discussion has highlighted the Unicode vs ASCII differences in detail.
ASCII was developed to encode text and numbers into a computer readable format. Since, ASCII was limited to a single language, Unicode came into being.
Unicode has three encoding standards, UTF-8, UTF-16 and UTF-32. UTF-8 is a superset of ASCII.
Today most of the websites are following UTF-8 encoding. It is being used by many browsers and operating systems also.
UTF-8 is recommended for encoding purpose because it is more secure, flexible and has high usability.
 Top 8 Interview Questions for High School Students Admission
Top 8 Interview Questions for High School Students Admission Difference Between ITX and ATX: ITX vs ATX Motherboards
Difference Between ITX and ATX: ITX vs ATX Motherboards












